
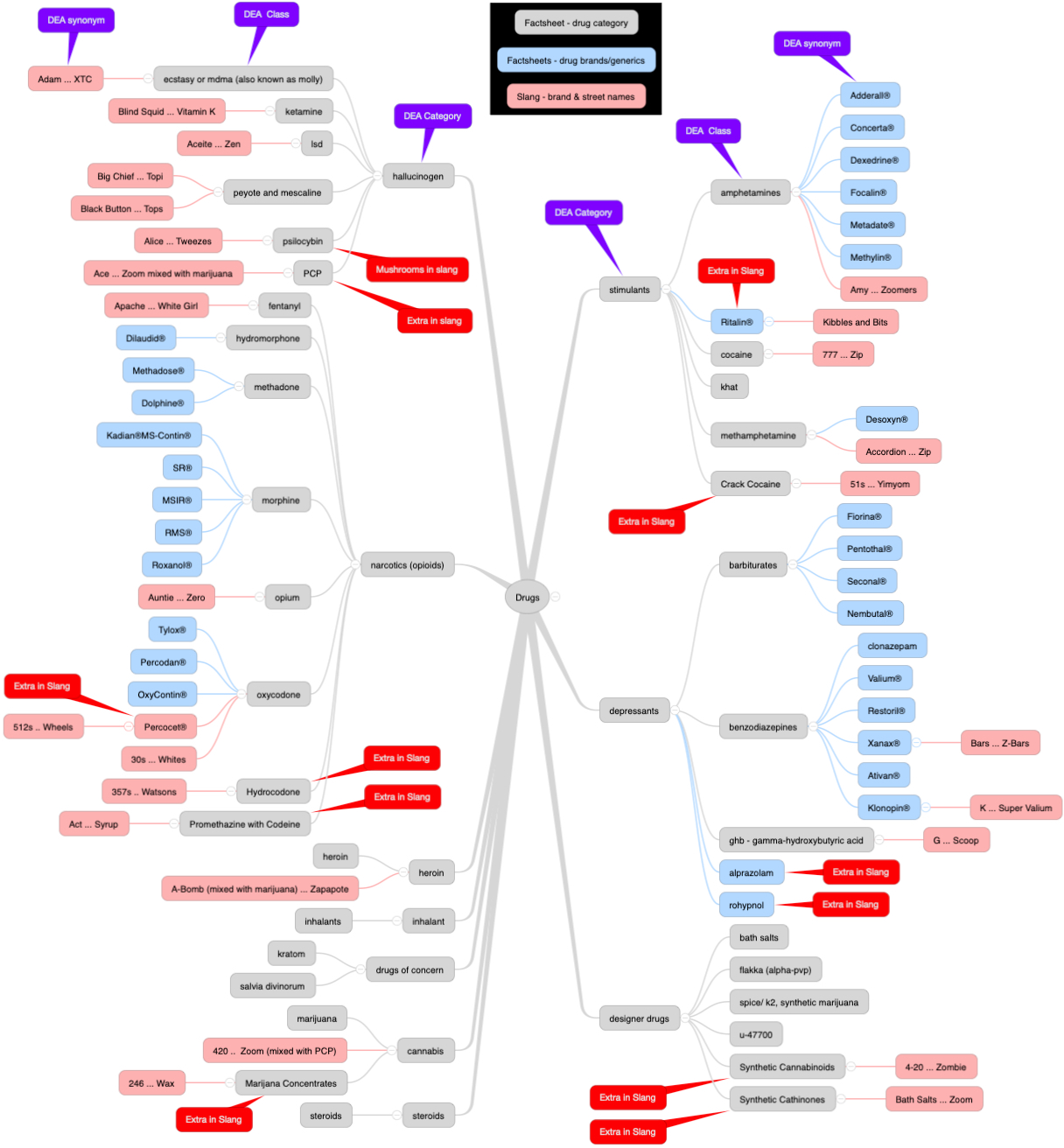
The goal of DOPE is to provide a structured vocabulary and tools to look up details on drugs tracked by the DEA. The data structure is:
Installation
Official Release
You can install the released version of DOPE from CRAN with:
install.packages("DOPE")Development Release
Run these two lines of code to install DOPE from GitHub (this requires RTools for Windows or Xcode for Mac to be installed on your computer):
if (!requireNamespace("devtools")) install.packages("devtools")
devtools::install_github("CTN-0094/DOPE")Examples
You can look up details on a drug with the lookup() function. It will check brand, generic and street names.
The lookup funciton supports vectorized lookups:
library(DOPE)
lookup("cheese", "pizza", "with", "a", "soda")
lookup(c("Buprenorphine", "Tramadol", "Bup/Nx"))If your only care about the class and/or category and/or if you search returns many matches you can use the compress_lookup() function to drop columns and then remove duplicate rows.
lookup("cheese", "pizza", "with", "a", "soda") %>%
compress_lookup(compressClass = FALSE,
compressCategory = TRUE,
compressSynonym = TRUE)DOPE now allows for parsing out drug names from a vector which contains free text with the parse() function. You can use it in conjunction withlookup() and compress_lookup()
data(drug_df)
parse(drug_df$textdrug[1:5]) %>%
lookup()Additional Information
For more information or to see detailed vignettes, please visit https://ctn-0094.github.io/DOPE/.